")

Creating a robots.txt file is a critical step for webmasters looking to guide search engine crawlers through their websites. This simple text file can mean the difference between a fully indexed site and one that inadvertently blocks crucial content from search engine visibility.
With the rise of online tools, you can now generate a robots.txt file instantly, streamlining the task of crawler management. Let’s explore how you can quickly create and customize a robots.txt file, ensuring your website’s content is crawled efficiently and securely.
How to generate a robots.txt file instantly?
To generate a robots.txt file quickly, you can use a free online generator. These tools often require you to simply list the directories or pages you wish to exclude from crawling and then produce the appropriate directives for you.
While the process is straightforward, it’s important to understand the implications of each directive you include in your file. A wrongly placed “Disallow” can prevent search engines from accessing content meant to be indexed, impacting your site’s SEO performance.
Once you have generated the content for your robots.txt file using the online tool, you will need to upload it to the root directory of your website. This will ensure that search engines can access and follow the instructions contained within the file.
What is a robots.txt file and why is it important?
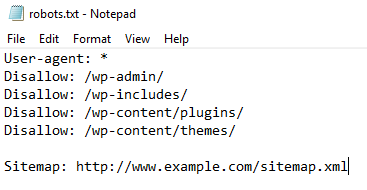
A robots.txt file is a plain text file that follows the Robots Exclusion Protocol. It instructs web crawlers, also known as user agents, which parts of a website they can or cannot process and index.
This file is fundamental for SEO because it allows site owners to control the crawl traffic and ensure that search engines spend their time and resources indexing the most important content. It can also be used to keep certain parts of your site private.
A well-configured robots.txt file can prevent search engines from accessing duplicate pages, special offers, or any other content that should not appear in search engine results, thereby enhancing the overall user experience.
How to write and submit a robots.txt file?
Writing a robots.txt file involves specifying two main components: the user agent and the disallow directives. For example, to block all web crawlers from a specific directory, your file should include the following lines:
User-agent: * Disallow: /directory-name/
On the other hand, to allow all crawlers full access, your robots.txt file will look like this:
User-agent: * Disallow:
After writing your file, submit it by placing it in the root directory of your website. This is typically done via FTP or through the file manager provided by your hosting service. It is essential to ensure that the file is named “robots.txt” and not something else, as this is the name search engines will look for.
How to use the disallow directive properly?
The “Disallow” directive is crucial in a robots.txt file. It tells search engines which paths on your site they should not visit. Using it correctly can protect sensitive data and ensure an efficient crawling process.
When employing the “Disallow” directive, remember that specificity is key. You can disallow a single page, an entire directory, or certain file types. However, be mindful not to inadvertently block pages that you want search engines to index.
Always double-check your robots.txt file to confirm that it only contains the directives you intended. A single typo can have significant consequences for your site’s search visibility.
What are the best practices for creating a robots.txt file?
When creating a robots.txt file, several best practices should be followed:
 Page 1 of 0 smallseotools blog.
Page 1 of 0 smallseotools blog.- Be specific: Use clear directives to avoid misinterpretation by search engines.
- Regularly update: As your website evolves, so should your robots.txt file to reflect changes in your site structure and content priorities.
- Use comments: Comments (lines starting with #) can help you and others understand the purpose of each directive.
- Check for errors: Utilize tools like Google Search Console to test your robots.txt file and identify any issues that could affect crawling.
- Keep it secure: Do not use the robots.txt file to hide sensitive information, as it is publicly accessible.
How to add a sitemap to the robots.txt file?
Including a sitemap in your robots.txt file is a straightforward process. A sitemap provides search engines with a roadmap of all the significant pages on your site, which can be beneficial for indexing purposes.
To add a sitemap, simply append a “Sitemap” directive to your robots.txt file, like so:
Sitemap: http://www.yourwebsite.com/sitemap.xml
This line should be added at the end of your robots.txt file. It’s a good practice to include a sitemap because it can help search engines discover new and updated content more efficiently.
Frequently asked questions about robots.txt files
Many webmasters and SEO specialists have questions about the intricacies of robots.txt files and their impact on a website’s search performance. Addressing these common queries can provide clarity and ensure that you are using your robots.txt file to its full potential.
Questions related to generating a robots.txt file
What is a robots.txt file?
A robots.txt file is a text file that webmasters create to instruct search engine bots on how to crawl and index pages on their websites. It is a crucial component of a website’s SEO strategy as it directs the crawlers to the content that should appear in search results.
This file is publicly accessible and found at the root of a website’s directory. It uses a simple syntax to communicate with user agents, specifying which areas of a site should not be processed.
Why is a robots.txt file important?
The importance of a robots.txt file lies in its ability to manage crawler traffic on your website. It ensures that search engines focus on indexing relevant content while avoiding unnecessary or sensitive areas. This can improve your site’s SEO by preventing the indexing of duplicate or irrelevant pages.
Additionally, it helps conserve your server resources by preventing crawlers from accessing heavy-load areas that could slow down your website.
How robots.txt file helps in SEO?
By effectively managing which pages are crawled, a robots.txt file can influence a website’s SEO. It helps search engines prioritize content that provides value to users, which can enhance the site’s visibility and rankings.
A well-configured file can also prevent search engines from indexing duplicate content, private pages, or pages with sensitive information, which could negatively impact SEO if left unchecked.
How to create a robots.txt file?
Creating a robots.txt file is a simple process. You can generate a robots.txt file instantly with an online tool or write it manually. The basic syntax includes a user-agent line, followed by disallow directives for the paths you want to block.
Once you have the content ready, save it as “robots.txt” and upload it to the root directory of your website. It’s important to review the file for accuracy before making it live to avoid any unforeseen issues with search engine indexing.
How to properly implement robots.txt rules?
Proper implementation of robots.txt rules involves carefully constructing the disallow directives to accurately reflect the content you want to block from search engine crawlers. Use wildcard characters wisely to match patterns and avoid blocking more than intended.
Regular testing and monitoring through tools like Google Search Console can also help you ensure that your rules are working as expected and not hindering your SEO efforts.
 Page 1 of 62 smallseotools blog.
Page 1 of 62 smallseotools blog.In conclusion, understanding the function and proper utilization of the robots.txt file is key to optimizing your website for search engines. By adhering to best practices and leveraging online tools to generate a robots.txt file instantly, you can take control of how search engines interact with your site’s content, ultimately boosting your online presence.